De constituenten van de Nederlandse zin en hun vorm
In dit hoofdstuk worden de bestanddelen ('constituenten') behandeld waaruit Nederlandse zinnen zijn opgebouwd. We zullen niet alleen verschillende manieren leren kennen om deze bestanddelen te onderscheiden, maar we zullen ook zien wat voor soorten constituenten er bestaan en wat hun onderlinge relatie is. Het doel van dit hoofdstuk is om te laten zien hoe de verschillende constituenten uiteindelijk de grootste constituent, namelijk de zin, vormen.
- Wat zijn constituenten?
- Constituenten herkennen
- Een andere notatie: boomdiagrammen
- Constituentensoorten
- Herschrijfregels
- Kern en modificeerder
- Recursieve regels
- De constituentenstructuur van zinnen: enkele voorbeelden
- Woordsoorten: functiewoorden en inhoudswoorden
- Subcategorisatie
- Structurele dubbelzinnigheden
- Leeswijzer
Wat zijn constituenten?
Elke zin is opgebouwd uit bepaalde bestanddelen, en hoewel er verschillende mogelijkheden zijn om de zinsdelen of constituenten van een zin te bepalen zoals in (1.1-4), zal elke spreker van het Nederlands intuïtief de voorkeur geven aan de structuur die door de haakjes in (1.1) is aangeduid:
(1)
- [De oude man][eet [een appel]]
- [De oude][man eet een] [appel]
- [De [oude man eet ]][een appel]
- De [oude][man [eet een]] [appel]
De haakjesstructuur in (1.1) duidt – heel globaal – aan dat de zin De oude man eet een appel uit twee constituenten bestaat: één, die aangeeft waarover in de zin iets gezegd wordt, en één, die aangeeft, wat er over gezegd wordt. De eerste constituent is in dit geval de oude man, over wie door de tweede constituent gezegd wordt, dat hij een appel eet. De haakjesstructuur laat zien dat deze tweede constituent zelf weer uit twee constituenten bestaat: eet en een appel. Dat hoeft niet zo te zijn; de tweede constituent kan ook uit een enkel woord bestaan:
(2) [De oude man][slaapt]
Natuurlijk kan elke complexe constituent zoals de oude man in een tweede stap zelf weer in kleinere eenheden onderverdeeld worden totdat er uiteindelijk alleen afzonderlijke woorden overblijven.
Het doel van zinsontleding of de analyse van de constituentenstructuur is om een complete zin op een verantwoorde manier in samenhangende bestanddelen onder te verdelen. Op deze manier willen we laten zien dat zinnen niet zomaar uit een willekeurige volgorde van woorden bestaan maar dat woorden deel uitmaken van bepaalde eenheden die zelf weer tot grotere bestanddelen behoren. Daarachter staat de gedachte van het creatieve vermogen van de taalgebruiker: Taalgebruikers zijn in principe in staat om elke willekeurige zin te produceren en te begrijpen, ook al hebben ze die nooit tevoren gehoord. Eveneens kunnen ze in principe oneindige zinnen produceren, bijvoorbeeld volgens dit schema:
(3) Anneke zei dat Pieter had gedacht dat ze de volgende dag zouden weten dat Hans zou ....
Er bestaat dus geen 'langste zin'. Dat in feite geen oneindige zinnen geproduceerd worden heeft met een aantal redenen te maken, waaronder restricties op de fysiologische spreekvaardigheid, de capaciteit van het geheugen van spreker en hoorder en uiteindelijk ook met het feit dat niemand het eeuwige leven heeft. De structuur van taal op zich zou echter de productie van oneindige zinnen toestaan.
Taalproductie en het begrijpen van taal kan dus geen kwestie zijn van reproductie en herkenning van reeds bekende zinnen. In plaats daarvan wordt elke zin op zich door de taalgebruiker gecreëerd (gegenereerd) en geïnterpreteerd. Elke taalgebruiker moet daarom kennis van bepaalde regels hebben die syntactische structuren genereren. Iedereen beschikt over deze regels zonder dat te weten. Deze kennis is dus onbewuste kennis. De tweede voorwaarde om zinnen te kunnen produceren is de kennis van woorden. Omdat het geheugen groot maar niet oneindig is, kunnen wij veel maar niet oneindig veel woorden in ons mentale lexicon opslaan. Deze beperkte hoeveelheid woorden in combinatie met een beperkt aantal regels stelt ons in staat om in principe oneindig veel en oneindig lange zinnen te produceren en te begrijpen.
Eén van de doelen van een syntactische analyse is het herkennen van deze regels, en de analyse van de constituenten is de eerste stap om dat te doen.
We hebben gezien, dat we de constituentenstructuur in (1.1) intuïtief boven de structuren in (1.2) – (1.4) verkiezen. Dat heeft vooral morfologische en semantische redenen: artikel (lidwoord), adjectief (bijvoeglijk naamwoord) en substantief (zelfstandig naamwoord) in de oude man stemmen wat betreft genus (woordgeslacht), namelijk "masculien" (mannelijk), en numerus (getal), namelijk "singularis" (enkelvoud), overeen. Een ander woord voor deze overeenstemming is congruentie. Ook in semantisch opzicht is de haakjesstructuur in (1) relevant: de eerste constituent heeft referentiële betekenis en noemt diegene over wie iets gezegd wordt, namelijk over de oude man. De tweede constituent heeft predicatieve betekenis en duidt aan wat er over de eerste gezegd wordt, namelijk dat de oude man een appel eet.
Constituenten herkennen
Een manier om vast te stellen wat de constituenten van een zin zijn, is om een complexe constituent door één enkel woord te vervangen:
(4) [De oude man][eet [een appel]] → [Hij][eet [een appel]]
De oude man wordt vervangen door het pronomen (persoonlijk voornaamwoord) hij. Deze test heet vervangingstest of pronominalisatietest: een opeenvolging van woorden die door een pronomen kan worden vervangen is een constituent.
Deze test is echter niet voldoende omdat er veel groepen van woorden zijn waarvoor geen mogelijkheid tot pronominalisatie bestaat. Een andere mogelijkheid is om constituenten te verplaatsen:
(5) [Gisteren][ging][Karel][naar de bioscoop] → [Karel][ging][gisteren][naar de bioscoop] → [Naar de bioscoop][ging][Karel][gisteren]
Met behulp van deze verplaatsingstest kunnen we vaststellen dat woorden of groepen van woorden die verplaatst kunnen worden een constituent vormen. Ook deze test is op zich niet voldoende: niet elke constituent is in elke positie toegestaan:
(6) *[Karel][gisteren][naar de bioscoop][ging]
("*" betekent dat het navolgende woord of de navolgende woordenreeks ongrammaticaal is, dus "fout t.o.v. de grammatica".)
Een derde mogelijkheid is de vraagtest: een constituent is iets waarnaar wij kunnen vragen.
(7)
- Wie komt er vanmiddag naar Berlijn? [Mijn moeder]
- Wat heb je daar gezien? [Het nieuwe boek]
- Hoe vond je dat boek? [Heel goed]
- Wanneer gaan we naar het feest? [Vanavond]
- Waarom heb je dat boek niet gekocht? [Omdat het heel duur is]
Deze test laat zien dat er nog andere soorten constituenten bestaan dan degene die die we tot nu toe hebben leren kennen: bijvoorbeeld temporele bepalingen (bijwoordelijke bepalingen van tijd) zoals in (7.4) of zelfs een hele bijzin zoals in (7.5).
De laatste test is de coördinatietest: woorden en woordvolgorden die gecoördineerd kunnen worden zijn constituenten:
(8)
- [[De oude man] en [de jonge man]][eten [een appel]]
- [Lust] [je] [[een ijsje] of [een biertje]]?
- [Ik] [hou van] [[wandelen] en [lezen]]
Een andere notatie: boomdiagrammen
De constituentenstructuur in (9.1) wordt door middel van haakjes aangeduid. Wanneer er echter sprake is van een complexere zin wordt het heel moeilijk om de constituentengrenzen zonder meer te kunnen herkennen, zie (9)b).
(9)
- [De oude man][eet [een appel]]
- [Hij [wist [dat [de kinderen] [met [de [[groene] en [blauwe] ballen]]] speelden]]]
Het is daarom soms makkelijker om een complexe structuur via een zogenaamde boomstructuur weer te geven, ook al neemt dat meer ruimte in beslag:
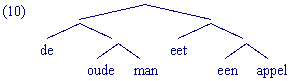

Constituentensoorten
We hebben hierboven al gezien dat zinnen uit meerdere constituenten bestaan en we hebben verschillende manieren leren kennen om constituenten te herkennen. Wat we echter nog niet weten, is wat voor soorten constituenten er precies zijn. Een basisprincipe luidt: wanneer constituenten elkaar kunnen vervangen zonder dat de zin ongrammaticaal wordt, vormen ze één syntactische categorie:
(12) Er loopt {een kat / een oude mevrouw met twee koffers / een dikke man} op straat
De meest gebruikelijke syntactische categorieën zijn:
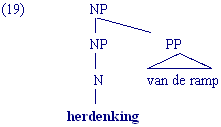
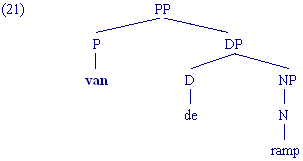
CP (complementizer phrase) [soms ook S voor sentence, zin] Er loopt een kat op straat; Hans koopt een boek; Het regent VP (verb phrase) slaapt; koopt een boek, is heel oud DP (determiner phrase) de oude man; een kind; oude mannen; hij; Maria AP (adjective phrase) oud; heel bijzondere; trots op de moeder NP (noun phrase) oude man; kind; herdenking van de ramp PP (prepositional phrase) met het mes; achter de deur N (nomen) auto; kind V (verbum) kopen; eten; slapen A (adjectief of adverbium) oud; dik; erg P (prepositie) onder; achter; op Det (determiner) de; het; een; vijf Comp (complementizer) dat; of
We kunnen nu de constituentenstructuur van de reeds bekende zin De oude man eet een appel nader specificeren:
(13) [[DeDET [[oudeA]AP [manN]NP]NP]DP [eetV [[eenDET][appelN]NP]DP]VP]CP
Herschrijfregels
De constituentenstructuur van het Nederlands vertoont een aantal regelmatigheden. Als we de lijst van de syntactische categorieën nog eens bestuderen, kunnen we al gauw zien waarom dat zo is: het zijn geen aparte categorieën maar ze staan in een nauw verband tot elkaar. Met behulp van de bepaalde syntactische regels, de herschrijfregels, wordt de interne opbouw van de categorieën beschreven en we kunnen zien hoe een constituentenstructuur gegenereerd ("voortgebracht") wordt.
Aan de linkerkant van de pijl staat een bepaalde constituent (een zogenaamde XP, waarbij de "X" voor C, V, N, A of P staat), aan de rechterkant staat de structuur die aan deze XP wordt toegekend. Zoals de voorbeelden in de lijst laten zien, bestaat er vaak meer dan een mogelijke structuur voor een bepaalde XP. Daar kunnen we rekening mee houden door de constituenten die niet aanwezig hoeven te zijn tussen ronde haakjes te zetten.
(14)
- DP → (Det) NP
- NP → (AP) N (PP)
De herschrijfregels in de pijlnotatie geven niet alleen aan wat voor constituenten een bepaalde XP bevat, maar ze laten daarnaast ook de interne volgorde van de constituenten zien. Volgens de herschrijfregel in (14.1) in combinatie met de regel in (14.2) moeten in een DP de determiner en het adjectief altijd aan het nomen voorafgaan. Dat dat klopt, kunnen we in de volgende voorbeelden zien:
(15)
- de oude man
- *oude de man
- *man de oude
- *man oude
- *man de
De volgorde "Det - AP - NP" is op zich niet vanzelfsprekend. In het Duits en het Engels vind je weliswaar dezelfde volgorderestrictie, maar er zijn ook andere talen zoals het Frans of het Spaans waar andere volgordes mogelijk zijn of zelfs de voorkeur krijgen:
- *der Mann alte
- *the man old
- l'homme extraordinaire (Frans)
[de man oude]- gamle mann-en (Noors)
[oud man-de]- los muchachos ricos (Spaans)
[de mannen rijken]- quegli occhi cilestrini (Italiaans)
[deze ogen hemesblauw]
Hieronder volgen de belangrijkste herschrijfregels voor het Nederlands:
- CP → (Comp) DP VP
- DP → (Det) NP
- NP → (AP) N (PP)
- VP → (DP) (PP) V
- VP → (CP) (PP) V
- PP → P DP
- AP → (AP) A (PP)
Kern en modificeerder
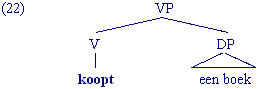
We weten dat niet alle constituenten van een bepaalde XP altijd aanwezig hoeven te zijn. De optionele toevoegingen hebben we tussen ronde haakjes geplaast. De verplichte kern van een XP wordt kern (of head) genoemd, de optionele toevoegingen heten modificeerders. Het ligt voor de hand dat een VP altijd een werkwoord, een V, bevat. De V is dus de kern van een VP, zoals uit de herschrijfregel blijkt. De kern van een NP is een N, de kern van een PP is een P enz.
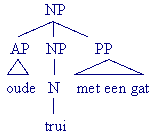
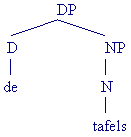
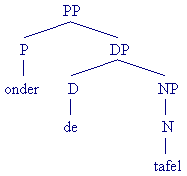
In de volgende voorbeelden is de kern (van de meest complexe XP) altijd vet gedrukt:
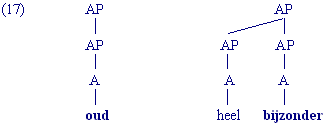
Een complexe constituent kun je ook op de volgende manier verkort noteren:
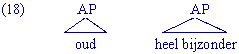
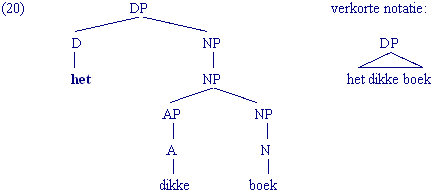
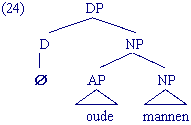
Let op: zoals uit de herschrijfregel voor de DP blijkt, hoeft de Det in het Nederlands niet verplicht aanwezig te zijn. Toch vormt de Det de kern van een DP. Dat heeft te maken met het feit dat er DPs zijn waar de Det niet gerealiseerd wordt, maar functioneel wel aanwezig is:
(23)
- de oude man
- de oude mannen
- een oude man
- ∅ oude mannen
Opdracht
- Geef voorbeelden van een AP, NP, DP en PP in de boomnotatie
- Benoem de volgende constituenten:
- achter de deur
- man met een mes
- ging boodschappen doen
- veel te hoog
- de boom
- dikke boeken
- dik boek
- een dik boek
-
- 1. PP 2. NP 3. VP 4. AP 5. DP 6. DP of NP 7. NP 8. DP

Recursieve regels
We hebben in het begin over het creatieve vermogen van de taalgebruiker gesproken, namelijk over het vermogen om zinnen te produceren en te begrijpen die nooit tevoren geproduceerd of gehoord zijn, en het vermogen om (in principe) oneindig lange zinnen te produceren. Voorbeelden van in principe oneindig lange zinnen zijn:
(25)
- Hans dacht dat Marie wist dat Pieter had gepland dat hij ...
- Dat is het boek over de huizen met de ramen met de knoppen ...
Met onze kennis van de herschrijfregels kunnen we nu dit vermogen beter verklaren. De constituentenstructuren van deze zinnen zijn dan:

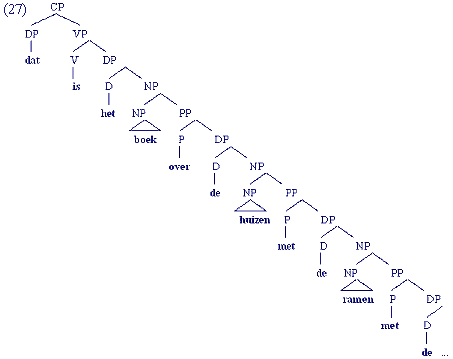
We kunnen duidelijk zien dat bepaalde constituenten steeds terugkeren. Dat heeft ermee te maken dat er herschrijfregels zijn waar de constituent die links van de pijl staat aan de rechterkant (naast anderen constituenten) nog eens voorkomt. Deze regels worden recursieve regels genoemd, dus regels die op zichzelf betrekking hebben. Om een heel lange zin te produceren heeft de taalgebruiker dus geen even lange en complexe herschrijfregel nodig, maar hij kan deze complexe structuur met behulp van enkele recursieve regels genereren.
Voor de voorbeelden in (25) hebben we twee resp. drie herschrijfregels nodig die samen een "recursieve set" vormen:
(28)
CP → (Comp) DP VP
VP → (CP) (PP) V(29)
PP → P DP
DP → (Det) NP
NP → (AP) N (PP)
De constituentenstructuur van zinnen: enkele voorbeelden
De volgende voorbeelden in de vorm van een boomstructuur laten zien hoe je met behulp van de herschrijfregels de constituentenstructuren van hele zinnen kunt genereren:
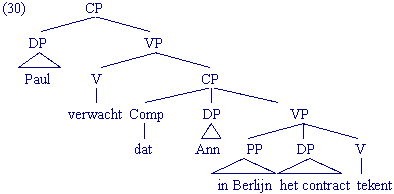
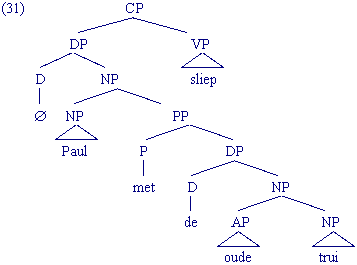
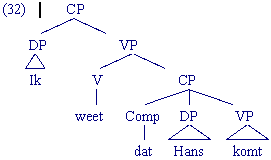
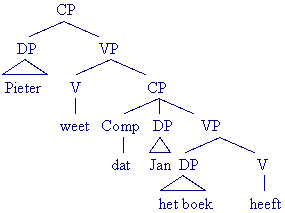
Opdracht
Geef de volgende zinnen in een boomstructuur weer:
- Pieter weet dat Jan het boek heeft.
- Filippa geeft het boek aan Marie.
- Ik denk dat Ann heel erg klein is.
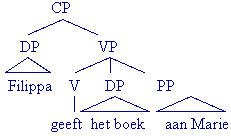
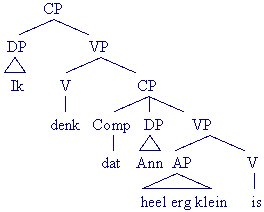
Woordsoorten: functiewoorden en inhoudswoorden
Bij voorbeelden (30) en (32) vinden wij het woord dat. Dat behoort tot de syntactische categorie COMP (complementizer) en vormt de kern van de CP. In tegenstelling tot vertegenwoordigers van de syntactische categorieën A, N en V hebben woorden zoals dat echter minder concrete, lexicale betekenis maar veeleer grammaticale betekenis: ze hebben een structurerende functie in de zin en worden daarom ook functiewoorden genoemd.
Andere soorten functiewoorden zijn:
lidwoorden de, het, een preposities (voorzetsels) op, onder, achter, in conjuncties (voegwoorden) en, maar, omdat pronomen (voornaamwoorden) ik, wij, mij, zich, elkaar
In zekere zin kunnen we ook de zogenaamde hulpwerkwoorden zoals hebben, zijn en worden tot de functiewoorden rekenen. In (33.1) kennen we aan het werkwoord hebben niet zijn lexicale betekenis toe (die wel bestaat, zie (33.2), maar de functie is hier om de grammaticale categorie "voltooide tijd" aan te geven.
(33)
- Marie heeft een broodje gegeten
- Marie heeft een broodje
Een fundamenteel verschil tussen functiewoorden en inhoudswoorden bestaat in het feit dat er bij de functiewoorden (in principe) geen nieuwe woorden meer bijkomen, ze vormen een gesloten klasse. De groep van de inhoudswoorden wordt daarentegen een open klasse genoemd omdat het aantal woorden onbeperkt is: bijvoorbeeld leenwoorden die uit andere talen in het Nederlands zijn opgenomen (zoals bureau, niveau, weekend, loser, junk). Dat komt vaak voor in samenhang met veranderingen in de maatschappij: samen met technische vernieuwingen zijn bijvoorbeeld woorden als computer, website en attachement ingevoerd.
Subcategorisatie
Inhoudswoorden hebben - in tegenstelling tot functiewoorden - geen grammaticale, maar een lexicale betekenis. In het mentale lexicon zijn voor elk woord de respectievelijke fonologische, semantische en syntactische kenmerken gespecificeerd. Op deze manier "weet" de spreker bijvoorbeeld dat nat tot de syntactische categorie A behoort en muis tot N. De specificatie van de syntactische categorie in het lexicon is belangrijk zodat altijd woorden van de juiste syntactische categorie op de juiste plaats binnen de constituentenstructuur terechtkomen: wanneer de structuur een woord van de syntactische categorie A verlangt, mag alleen een adjectief op deze plaats terecht komen. Dat is bijzonder belangrijk in verband met de structurele subcategorisatieregels: werkwoorden verschillen van elkaar wat betreft het aantal en type aanvullingen.
(34)
- Janneke ziet een boek
- *Janneke ziet een boek een broek
- *Janneke ziet
(35)
- Janneke slaapt
- *Janneke slaapt een boek
(36)
- Janneke geeft een boek aan Marie
- *Janneke leest een boek aan Marie
Transitieve (overgankelijke) werkwoorden zoals zien vereisen precies één NP als aanvulling, zie (34); intransitieve (onovergankelijke) werkwoorden zoals slapen veroorloven geen aanvulling (zie (35)) en ditransitieve werkwoorden zoals geven hebben er twee van nodig. Daarnaast zijn er werkwoorden die geen NP maar een PP subcategoriseren, zoals rekenen op iets. Soms is er een aanvulling niet verplicht maar optioneel, zoals bij laten zien:
(37) Janneke laat de foto's (aan haar moeder) zien
De lexicale informatie over de subcategorisatierestricties wordt op de volgende manier genoteerd; optionele aanvullingen staan tussen ronde haakjes:
(38) zien: __ DP; laten zien: __ DP (PP)
De aanvullingen waarover er in het lexicon iets vermeld staat, heten (verplichte of optionele) complementen van een werkwoord. Adjuncten daarentegen zijn aanvullingen die extra informatie over de handeling geven, bijvoorbeeld waar een handeling plaats vindt of op welke manier iets wordt uitgevoerd. Omdat adjuncten in principe aan elk werkwoord kunnen worden toegevoegd, staat er in de beschrijving van de afzonderlijke werkwoorden in het mentale lexicon niets over hen vermeld, in tegenstelling tot informatie over de complementen. Er bestaat dus ook geen beperking op het aantal mogelijke adjuncten:
(39) Janneke heeft gisteren achter de deur heel lang met Marie gekrenkt op haar echtgenoot gewacht.
Structurele dubbelzinnigheden
Soms zijn zinnen met afzonderlijke constituentenstructuren uiterlijk identiek, ze hebben dus identieke oppervlaktestructuren maar aparte dieptestructuren. Een voorbeeld van een dubbelzinnige of ambiguë zin vind je in (40):
(40) (...) omdat de man de vrouw met de wandelstok slaat
Deze zin heeft twee mogelijke interpretaties: of de man slaat de vrouw met behulp van de wandelstok of de man slaat de vrouw die een wandelstok heeft. Aan deze twee interpretaties liggen de volgende constituentenstructuren ten grondslag:
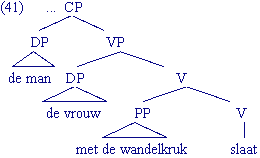

Dit type dubbelzinnigheid heet structurele dubbelzinnigheid omdat de ambiguïteit uit de dieptestructuur van de zinnen voortkomt. Ze heeft niets te maken met de betekenis van de afzonderlijke woorden, in tegenstelling tot zinnen die dubbelzinnig zijn op grond van de semantische ambiguïteit van een van hun woorden, zoals in de volgende zin:
(43) Het geld ligt op de bank
Met bank wordt hier of een meubelstuk of een financiële instelling bedoeld, en al naargelang deze keuze wordt dan de rest van de zin geïnterpreteerd, vooral wat precies de betekenis van liggen in dit verband is.
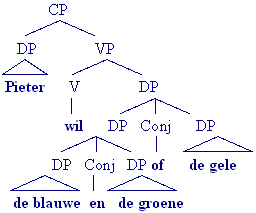
Opdracht
Geef de mogelijke onderliggende dieptestructuren voor de volgende ambiguë zin: Pieter wil de blauwe en de groene of de gele
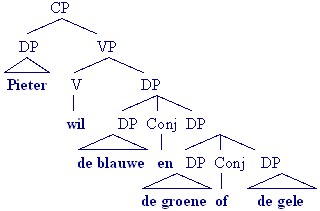
Leeswijzer
Voor constituenten en constituentenstructuur zie het hoofdstuk over syntaxis in Neijt, Rodman & Fromkin 1994, een stuk met een generatieve aanpak (niet helemaal up to date maar didactisch goed opgebouwd en met opdrachten), Appel et al. 2002 en Kerstens & Ruys 1994, eveneens met opdrachten, en het hoofdstuk "Syntaxis" in Kerstens et al. 1997. Zie daar en in Neijt, Rodman & Fromkin 1994 ook voor de overwegingen over taalvermogen.