TextSTAT - Simple Text Analysis Tool
Concordance software for Windows, GNU/Linux and MacOS
TextSTAT is a simple programme for the analysis of texts. It reads plain text files (in different encodings) and HTML files (directly from the internet) and it produces word frequency lists and concordances from these files. This version includes a web-spider which reads as many pages as you want from a particular website and puts them in a TextSTAT-corpus. The new news-reader, too, puts news messages in a TextSTAT-readable corpus file.
TextSTAT reads MS Word and OpenOffice files. No conversion needed, just add the files to your corpus...
In TextSTAT you can use regular expression which provides you with powerful search possibilities. The programme is multilingual. Because it uses Unicode internally, TextSTAT can cope with many different languages and file encodings.
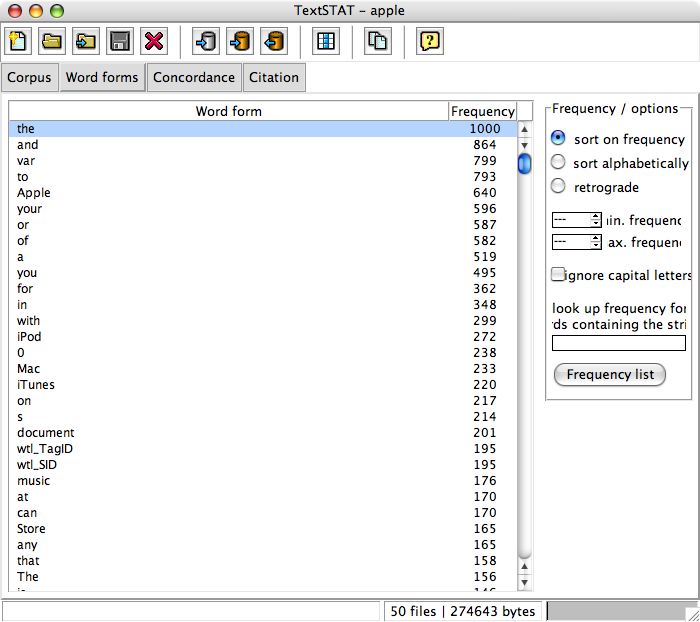
To give you an impression of how TextSTAT looks, you'll find a some screenshots here:
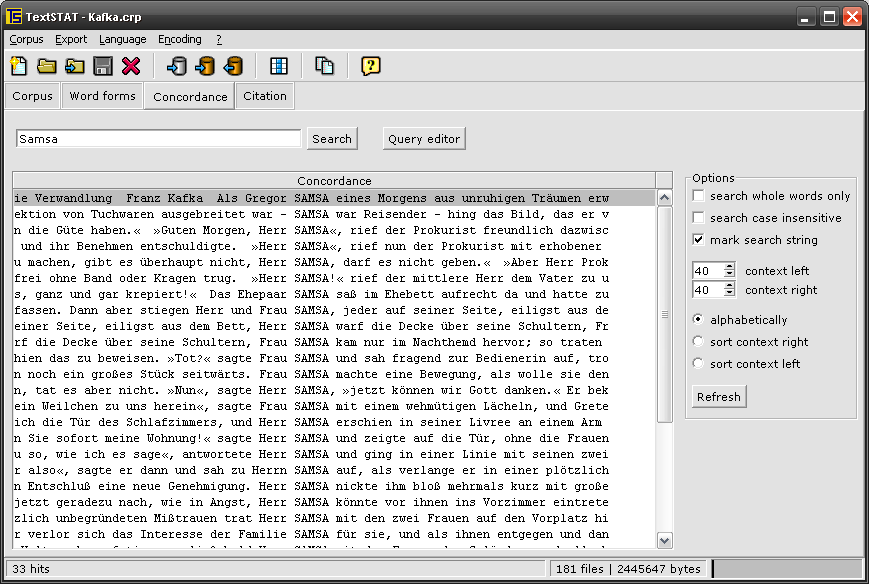
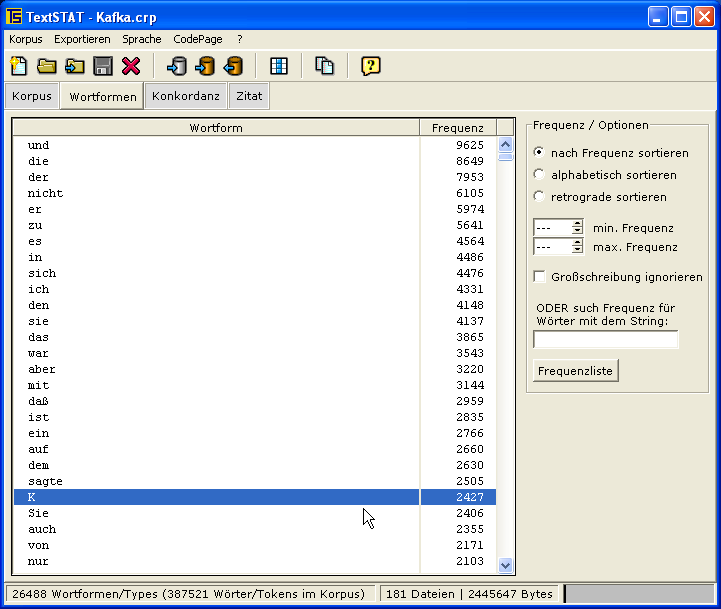
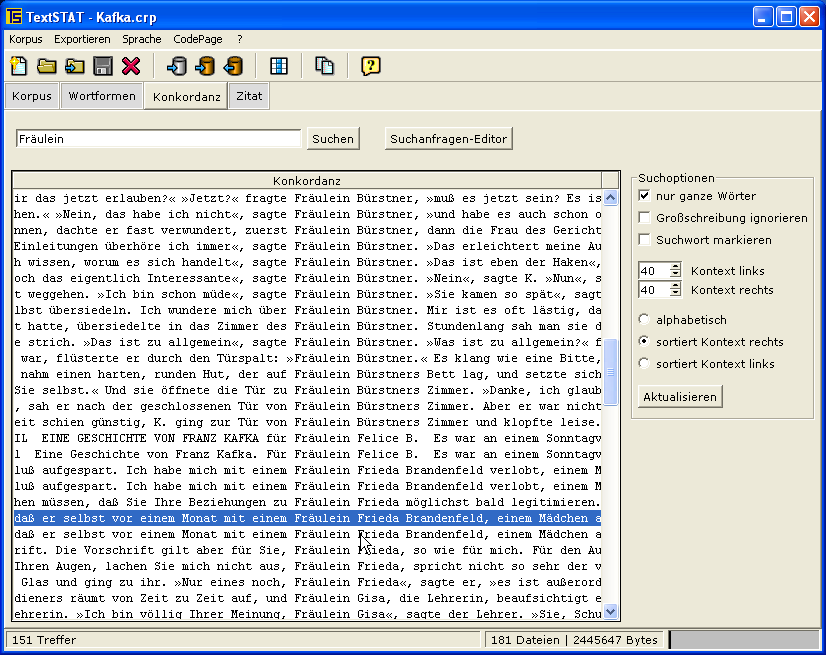
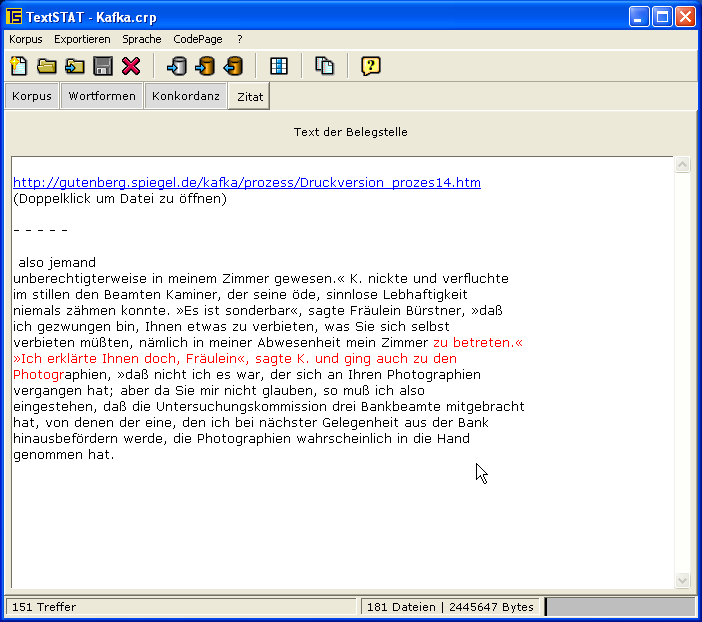
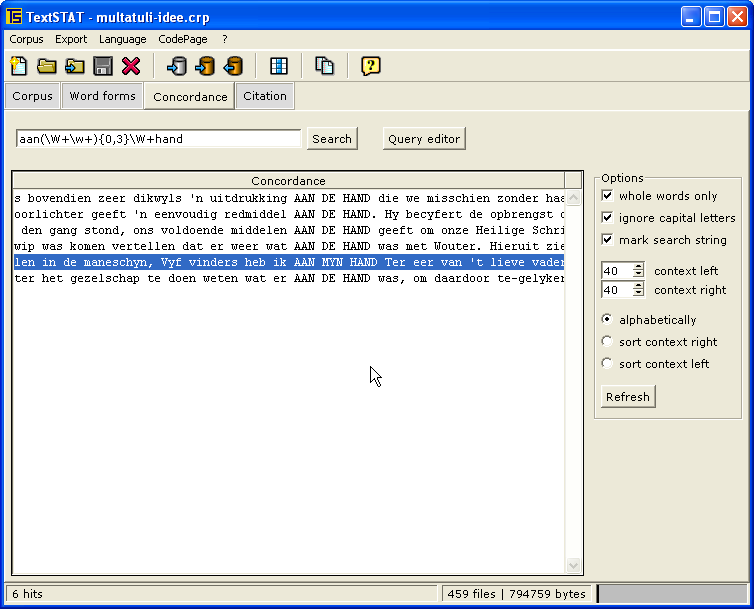
Windows XP (German): word frequencies, concordance, search term in context, concordance (English);
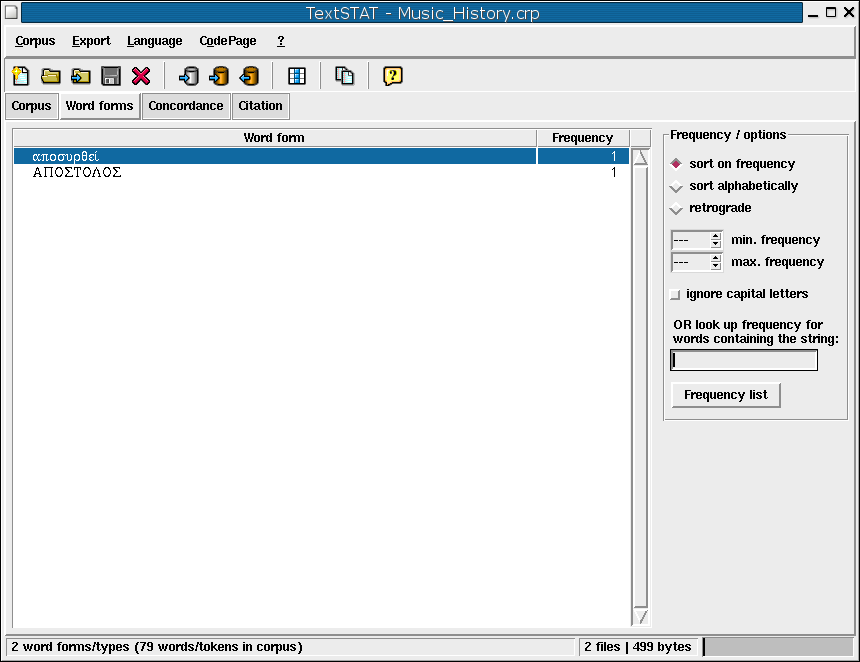
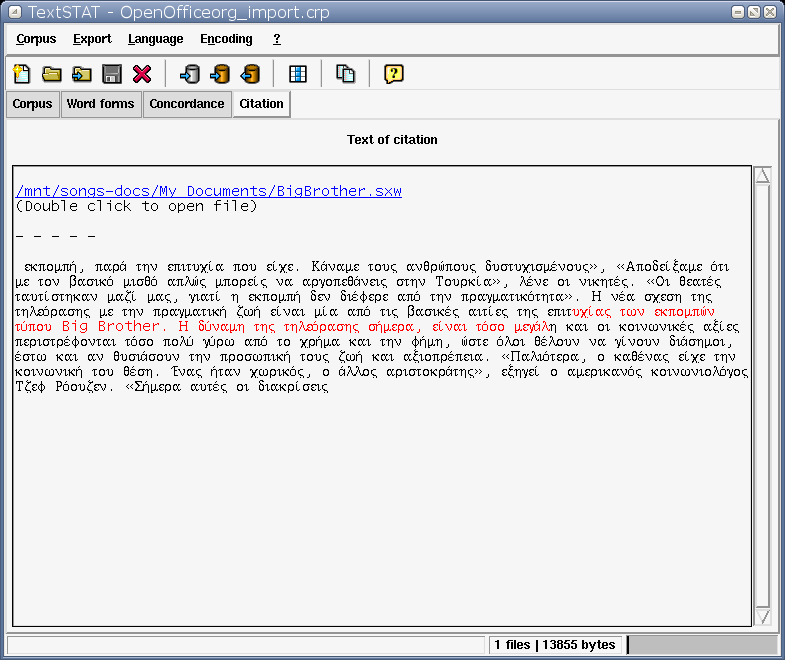
Linux (English/Greek): word forms/fequencies, citation/context (thanks to Nikos Kouremenos).
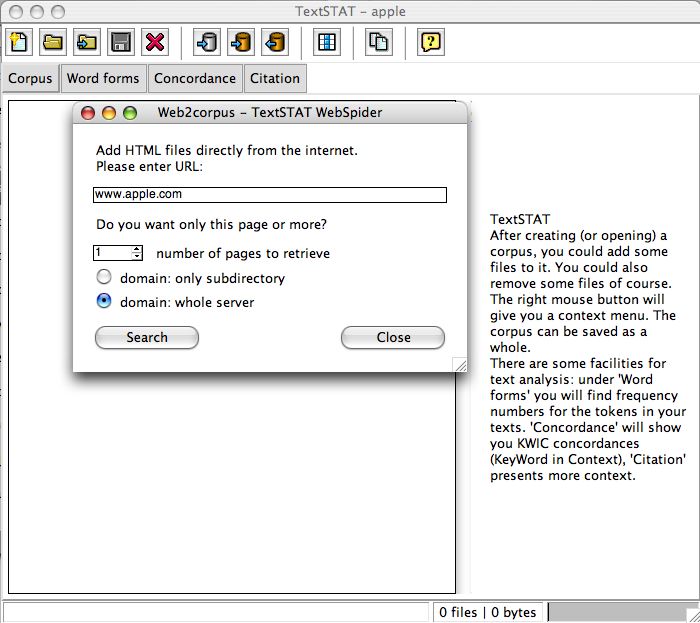
MacOS X (Englisch): webspider, word forms/fequencies (thanks to Eric Nieuwland).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Documentation:
For a first introduction to TextSTAT, please refer to the Quickstart Guide to text analysis with TextSTAT from the 'Humanities Resource Centre' at Princeton University. And Gena Bennett wrote a useful TextSTAT 2.7 User's Guide.
There is also a nice video tutorial by Zarah Weiß, available via YouTube.
NEW: TextSTAT 3 (beta)
There are some drastical changes in this new version of TextSTAT, most of them internal. Some of the major changes:
- TextSTAT now works with Python 2 (>= 2.7) and - even better - with Python 3 (>= 3.4). Besides Python you will need Tkinter (for the GUI), which is included in most distributions. For full functionality on MS Windows, you will also need to install the Python Windows-Extensions (grab the version that fits your Python installation).
- The graphical user interface has been modernized. Therefore, the programme should run much smoother not only under Windows and Linux, but especially on MacOS X computers.
- The database format has changed (TextSTAT now uses SQLite). This should have positive consequences especially for bigger corpora. Existing corpora from a previous version, therefore, cannot be opened directly, but have to be imported into a new database (should work painlessly). The default file suffix has changed to .crp3 in order to keep the different versions apart.
- Files can now be edited within the corpus. This is sometimes necessary, especially for files that have been downloaded from the internet (e.g. remove advertisement of navigation elements). Just click on the filename in the corpus tab.
- Linux only: PDF files can be added to a corpus directly.
- There have been many other changes, e.g. with respect to the conversion of texts or the export of concordance lists. The license has been changed to a Creative Commons licens (CC BY-SA)
The new version is available for download here. Right now only as a script version (you will need Python). Binary versions for Windows and MacOS will follow.
- Download: TextSTAT 3.0 (beta) sourcecode (ZIP-file, approx. 80 KB, September 02, 2015)
ATTENTION: This is a beta version which might still contain bugs. The database format might be subject to change.
Feedback on this new version of TextSTAT is appreciated!
The latest version 2.9 of the programme is mostly a bug fix release. Don't expect new features. TextSTAT is now available with the following programme languages: English, German, Dutch, Potugese, Spanish, Catalan, French, Italian, Galician, Finnish (Suomi), Polish, Czech.
Download (binary version for MS Windows XP/Win7):
TextSTAT 2.9c for Windows (ZIP file, approx. 8 MB, Feb 20, 2014)
This version includes everything you need to use TextSTAT with Windows. It comes as a single installation file. To install the programme, just unpack the file to a directory of your choice. To run TextSTAT, change to that directory and doubleclick on 'TextSTAT.exe'. That's it. If you decide to have a shortcut from the desktop or the start menu, you'll have to create the shortcut yourself.
Uninstall: Since TextSTAT doesn't change your registry or other system components, you can savely delete the directory in which you installed the programme. After that, TextSTAT will be completely removed from your system.
Download (Python Sourcecode):
TextSTAT 2.9c Sourcecode (ZIP file, 150 KB, Feb 20, 2014)
TextSTAT is written in Python and should run everywhere where Python runs. It has been tested with Windows XP and Linux. And it also runs on MacOS X.
You will need to install Python in order to use the programme (TextSTAT.pyw). It will run with Python versions > 2.5, the most recent version is 2.7 (TextSTAT will NOT work with 3.0). On Windows you could use the ActivePython distribution which contains everything you need (Windows extensions, Tkinter). With Linux and Mac there are of course no Windows Extensions - so you won't have export to MS Word and Excel. Except for that TextSTAT should run just fine on GNU/Linux and MacOS X. All you need is an up-to-date Python distribution (preferably 2.7), with Tkinter installed (which is not always the case, especially on Mac systems).
(Comparative) reviews of TextSTAT:
- Bennett, Gena R. (2010), Using Corpora in the Language Learning Classroom: Corpus Linguistics for Teachers. Ann Arbor, Michigan: University of Michigan. pp. 144. ISBN 978-0-472-03385-0. (Link)
- Aldo Benini (2010), Text Analysis under Time Pressure Tools for humanitarian and development workers. Washington, DC. (Link)
- Krajka, Jarosław (2007), Corpora and Language Teachers: From Ready-Made to Teacher-Made Collections. CORELL: Computer Resources for Language Learning 1, 36-55. (Link)
- Daniel Wiechmann & Stefan Fuhs (2006), in: Corpus Linguistics and Linguistic Theory 2-1, 107-127. (Link)
- Luciana Diniz (2005), in: Language Learning & Technology Vol. 9, No. 3, pp. 22-27. (Link)
The old 1.52 version is still available: TextSTAT 1.52 for Windows (ZIP file, 2.3 MB). You can read the documentation for TextSTAT (outdated) online.
TextSTAT is free software. It may be used free of charge and it may be freely distributed provided the copyright and the contents of all files, including TextSTAT.zip itself, are unmodified. Commercial distribution of the programme is only allowed with permission of the author. Use TextSTAT at your own risk; the author accepts no responsibility whatsoever. The sourcecode version comes with its own license.
Questions, problems, suggestions? Please contact
Matthias Hüning, <matthias.huening@fu-berlin.de>